SpringAI - 多模态(Multimodality)
多模态
AI模型的多模态
在前面的学习中我们只使用到了文本内容的输入与AI进行交互,那文本输入就算是一种模态。
那如果某个AI不仅仅能理解文本,还能理解图像、音频、视频等输入,那这个AI模型就支持了多模态。
现在能支持多模态的AI模型,在SpringA的文档上看到如下:
例如 OpenAI 的GPT-4o、Google 的Vertex AI Gemini 1.5、Anthropic 的 Claude3,以及开源模型 Llama3.2、LLaVA 和 BakLLaVA,都能接受文本、图像、音频和视频等多种输入,并通过整合这些输入生成文本响应。
之前的案例中都是使用的Deepseek模型,只能理解文本一种模态。今天的案例将使用OpenAI的模型,应该是GPT-4。
SpringAI实现多模态
如何实现的?
在学习提示词的时候,也就是“Prompt(一)”中学习
Message族谱那里,应该提到了提示词消息是被分成了Message和MediaContent多媒体内容两块。多模态就是通过
MediaContent来实现的,Message的类图再放一下。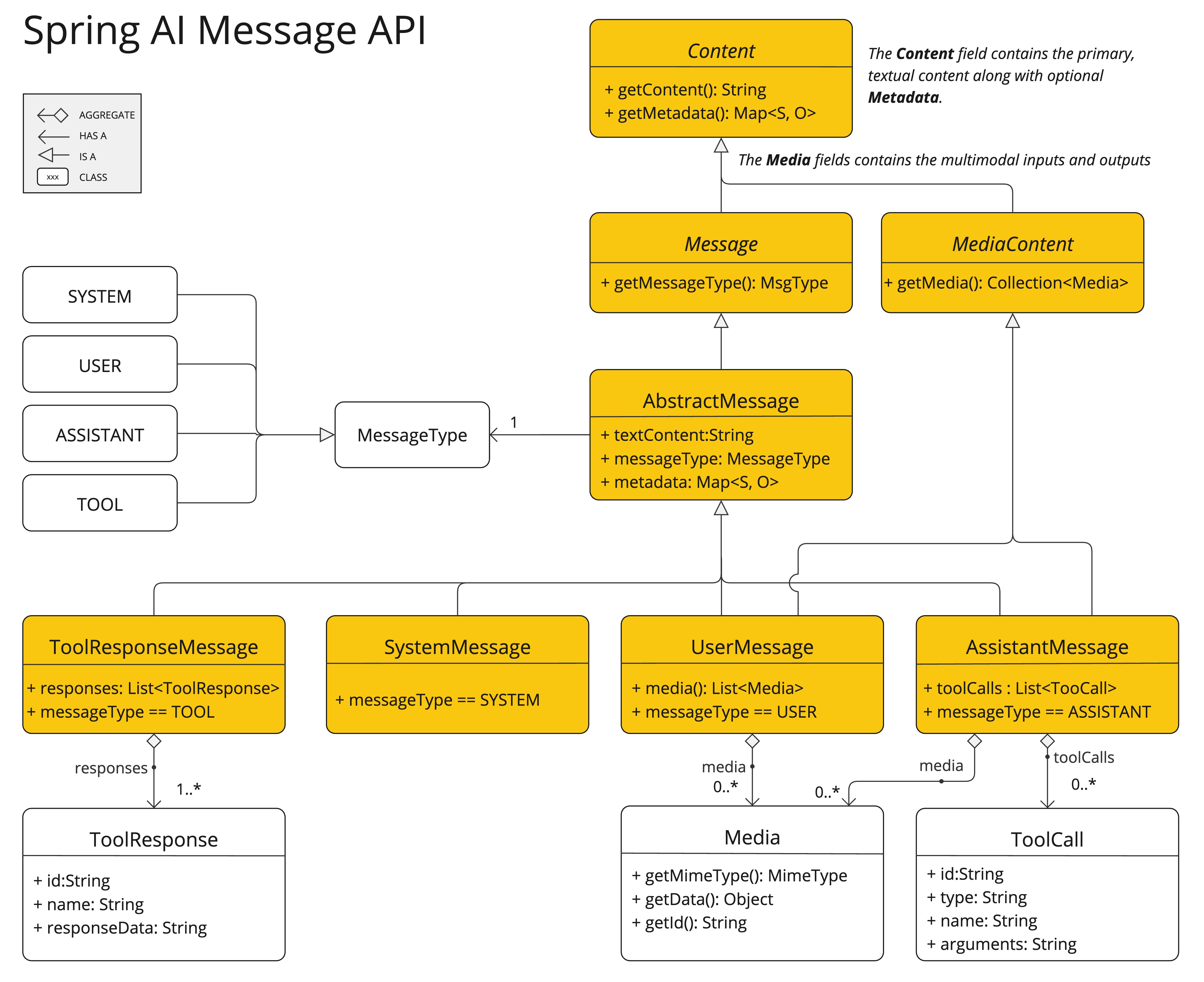
可以看到
UserMessage和AssistantMessage是实现了多模态内容的,注意⚠️:其他两个Message是不具备的。通过
media字段添等多模态内容的。在Media中通过MimeType来指定多模态的类型。
如何使用
这里我们使用OpenAI模型,同时输入文本和一张图像。需求如下:
输入文本要求解释图像中的内容,并根据内容创作一篇短篇文章。
图像如下:

创建OpenAI的
ChatClient。依赖跟配置在学习“ChatClient(一)”的时候已经引入过了。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
public class MultimodalityClientConfiguration {
public ChatClient multimodalityClient(OpenAiChatModel chatModel) {
return ChatClient.builder(chatModel)
// 添加 Advisors
.defaultAdvisors(spec -> {
spec.params(Map.of(
// 放置客户端名称
ContextKeys.ClientName.name(), "multimodalityClient"
));
spec.advisors(
new LogExampleAdvisor() // Log
);
})
.build();
}
}把图片文件放在项目的
resources的./img/目录下调用案例。通过
Resource读取文件。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
public class MultimodalityExample {
private final ChatClient multimodalityClient;
private Resource imgResource;
public void example() {
String user = """
1. 请解释图中有什么内容?
2. 请围绕图中的内容帮我写一篇100字左右的文章,要有情感共鸣。
""";
String content = multimodalityClient.prompt()
.user(userSpec ->
userSpec.text(user)
.media(MimeTypeUtils.IMAGE_PNG, imgResource))
.call()
.content();
}
}输出结果。可以看到按照输入的文本中
1.解释了图的内容,也按照2.写了短篇文章。1
2
3
4
5
6
7
8
9
10
11
12
13
142025-07-07T17:54:28.763+08:00 INFO 52441 --- [spring-ai-example] [ main] c.s.a.e.advisor.three.LogExampleAdvisor :
Chat client request to AI
prompt text -> 1. 请解释途中有什么内容?
2. 请围绕图中的内容帮我写一篇100字左右的文章,要有情感共鸣。
context -> {
"ClientName" : "multimodalityClient"
}
2025-07-07T17:54:37.450+08:00 INFO 52441 --- [spring-ai-example] [ main] c.s.a.e.advisor.three.LogExampleAdvisor :
Chat client response from AI
output text -> 1. 图中内容表达了在迷雾缭绕的山林中,主人公面对未知的挑战与自我反省。文字中提到的“走不出的浪浪山”和“山的后面是什么”暗示了对未来的迷茫与探索的渴望,同时也引发了对自我认知的深思。
2. 在这片神秘的山林中,迷雾仿佛隐藏着无尽的可能与未知的未来。走不出的浪浪山,正如人生的困境,让我感受到无力与孤独。然而,正是这片朦胧的山水,激起了我心中的勇气与希望。面对未知,我不再畏惧,因为每一步都是对自我的探索。山的背后或许有风景,也有挑战,唯有勇敢前行,方能发现真正的自我。无论未来如何,我相信,心中那份向往将引领我走出迷雾,迎接生命的每一次蜕变。
context -> {ClientName=multimodalityClient}
总结
MediaContent可以看作是提示词中的一部分吧。- 只是之前学习
Prompt使用的是文本模态的提示词。 - 使用
MediaContent后可以输入图片、音视频等模态的提示词了。 - 前提是需要AI模型自身支持多模态。
最后
- 这篇记录的内容不多,其实就是提示词
Prompt的扩展延续。 - 在具备多模态后,还叫“提示词”就显得局限了,以后就都叫“提示”。
- 接下来学习AI模型的封装
ChatModel,看看SpringAI是将模型封装后提供了哪些能力。 - 所有案例的源码,都会提交在GitHub上。包:
com.spring.ai.example.multimodality